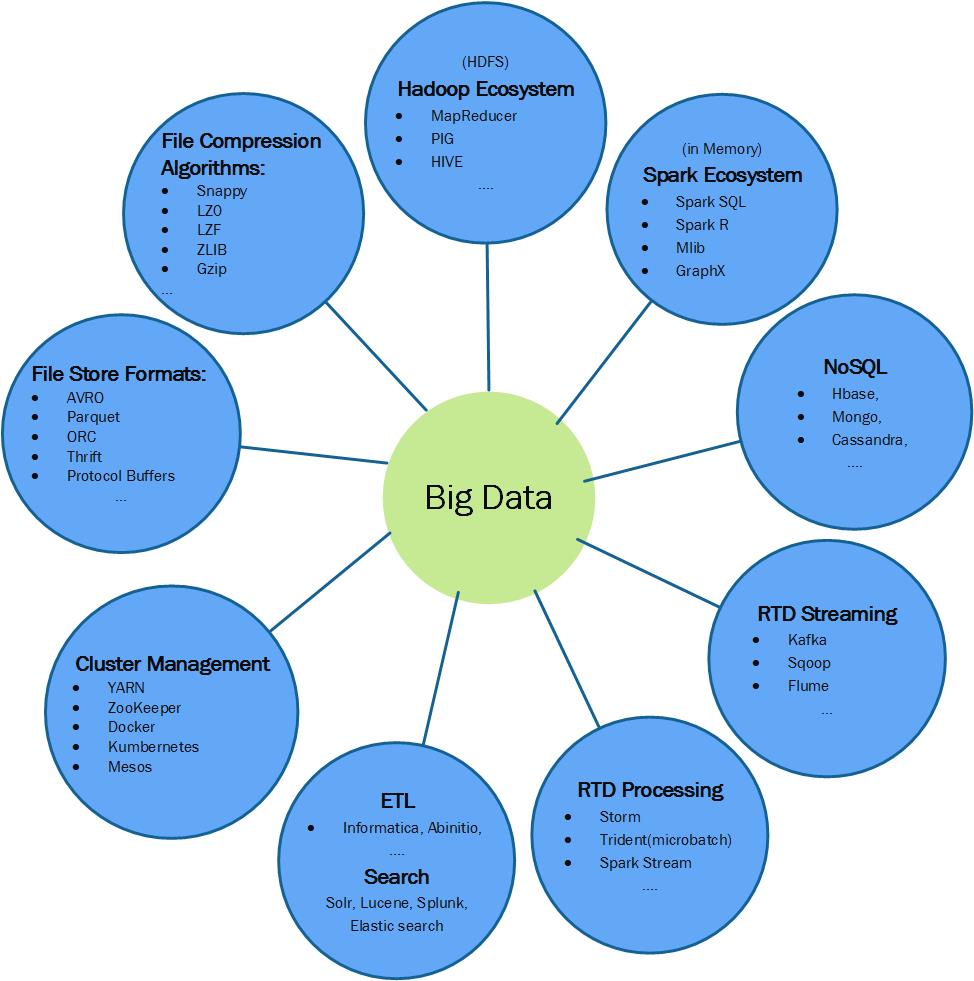
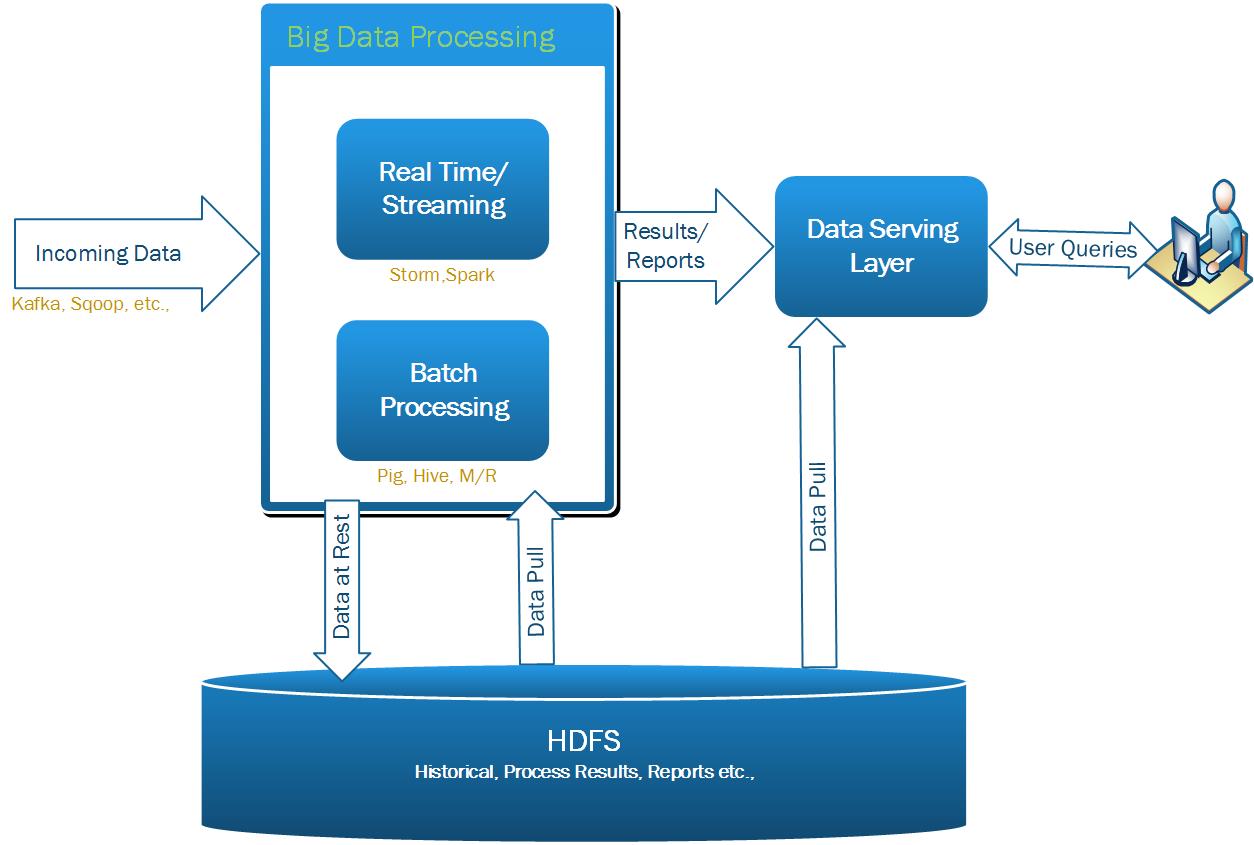
Polar offers cutting edge open source big data Technologies-as-a-Service to your applications. The Big Data Landscape includes the Hadoop ecosystem, Cassandra, Mongo, the Spark ecosystem, Solr, Kafka and Elastic search.
Ourexpert Big Data team delivers innovative solutions to solve difficult high-volume, low-latency, analytics, business intelligence, machine learning and other problems utilizing Big Data techniques.
Theteam delivers large-scale programs that integrate processes with technology to help our clients achieve high performance. We design, implement and deploy custom applications on Hadoop. Polar Big Data Services include implementation of complete Big Data solutions, data acquisition, storage, transformation, and analysis. We also design, implement and deploy ETL to load data into Hadoop.